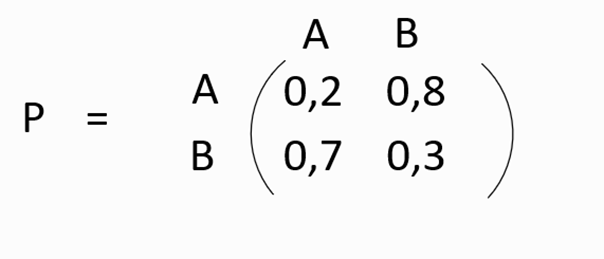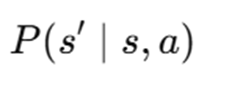1 . Markov chain :
A Markov chain is a mathematical model that describes a stochastic process in which the future state depends only on the current state, not on previous states. This principle is called the Markov property.
Markov chains are used in:
- Traitement du langage (Hidden Markov Models – HMM):
A Hidden Markov Model (HMM) is an extension of a Markov chain where states are hidden (not directly observable).
They are used for:
Speech recognition
Handwriting recognition
DNA sequence analysis
Activity detection (video, sensors)
Grammatical analysis in Natural Language Processing (NLP)
- Reinforcement learning — MDP (Markov Decision Process):
What is a Markov Decision Process (MDP)?
A Markov Decision Process (MDP) is a mathematical model used to represent sequential decision-making in an uncertain environment.
It is based on Markov's property:
The next state depends only on the current state and the chosen action, not on the entire history.
Reinforcement learning — MDP (Markov Decision Process)
The 4 components of a MDP
A MDP is defined by the tuple:
(S, A, P, R, γ)
Reinforcement learning — MDP (Markov Decision Process)
The 4 components of a MDP

S, A, P, R, γ)
1) S — Set of states:
Example :
Video game: player position, goal, game info
What an agent can do in a given state.
Examples:
Move forward, turn, jump
Buy, sell
Choose a direction
Apply a treatment
Shoot, defend (game)
2) A- Sets of actions
What an agent can do in a given state.
Examples:
Move forward, turn, jump
Buy, sell
Choose a direction
Apply a treatment
Shoot, defend (game)
3) P- probability:
This is the probability of transitioning to the state S’ si on exécute l’action S if we execute the action a:
The environment can be:
Deterministic: 100% certain outcome
Stochastic: the action yields an uncertain (realistic) outcome
Example for a robot:
Action: move forward
→ 80%: move forward
→ 20%: slide left
4) R- Reward function:
The reward measures the immediate quality of a transition.
This is what the agent tries to maximize.
Examples:
+10 when a robot reaches the exit
-1 for each wasted step
+100 for a win, -100 for a loss
+1 if the wallet makes money
=>The reward guides learning.
5) Y- Discount factor:
It controls the importance of the future:
if γ is close to 1 → the agent thinks "long-term"
if γ is low → the agent prioritizes immediate rewards
Robotics: Sequential Decisions in Uncertain Environments:
A robot operates in a world where:
limited perception: It cannot see everything ,
Inaccuracy : Its sensors are noisy
Uncertainty :its actions do not always produce the expected result .
Therefore, it must reason probabilistically=>
Markov's hypothesis states:
The future state depends only on the present state and the current action.
- Simple text generation using Markov strings:
Text, music, poems, phrases "imitating" a style.
- Model learning from a corpus
We start with an initial word (“The”).T hen we draw the next word according to probabilities:
"the" → "cat" (0.20)
→ "dog" (0.10)
→ "more" (0.05)
Example:
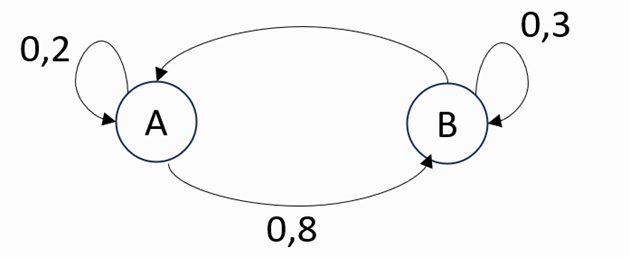
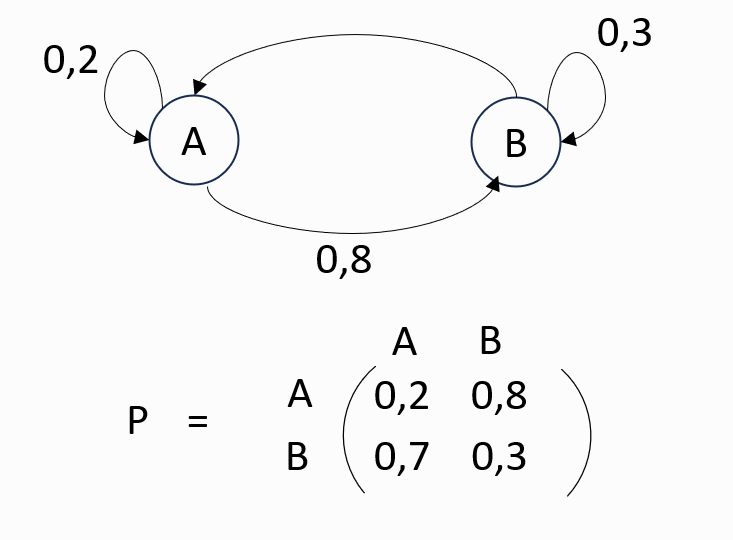
We consider the following Markov chain:
2. Main components:
· States: The different possible situations in the system.
· Transition probabilities: The probabilities of moving from one state to another.
· Transition matrix: A matrix that includes all the probabilities of transition between states.
3. Properties:
Limited memory: Only the present state is used to predict the future.
Evolution over time: The system evolves from one state to another with each "step"
4.Markov chain & IA:
Markov chains play a fundamental role in several areas of AI. They are involved in uncertainty modeling, prediction, sequential decision-making, and even machine learning.
5.Applications:
Markov chains are used in:
-
Traitement du langage (Hidden Markov Models – HMM):
A Hidden Markov Model (HMM) is an extension of a Markov chain where states are hidden (not directly observable).
They are used for:
- Speech recognition
- Handwriting recognition
- DNA sequence analysis
- Activity detection (video, sensors)
- Grammatical analysis in Natural Language Processing (NLP)
Example:
We consider the following Markov chain: